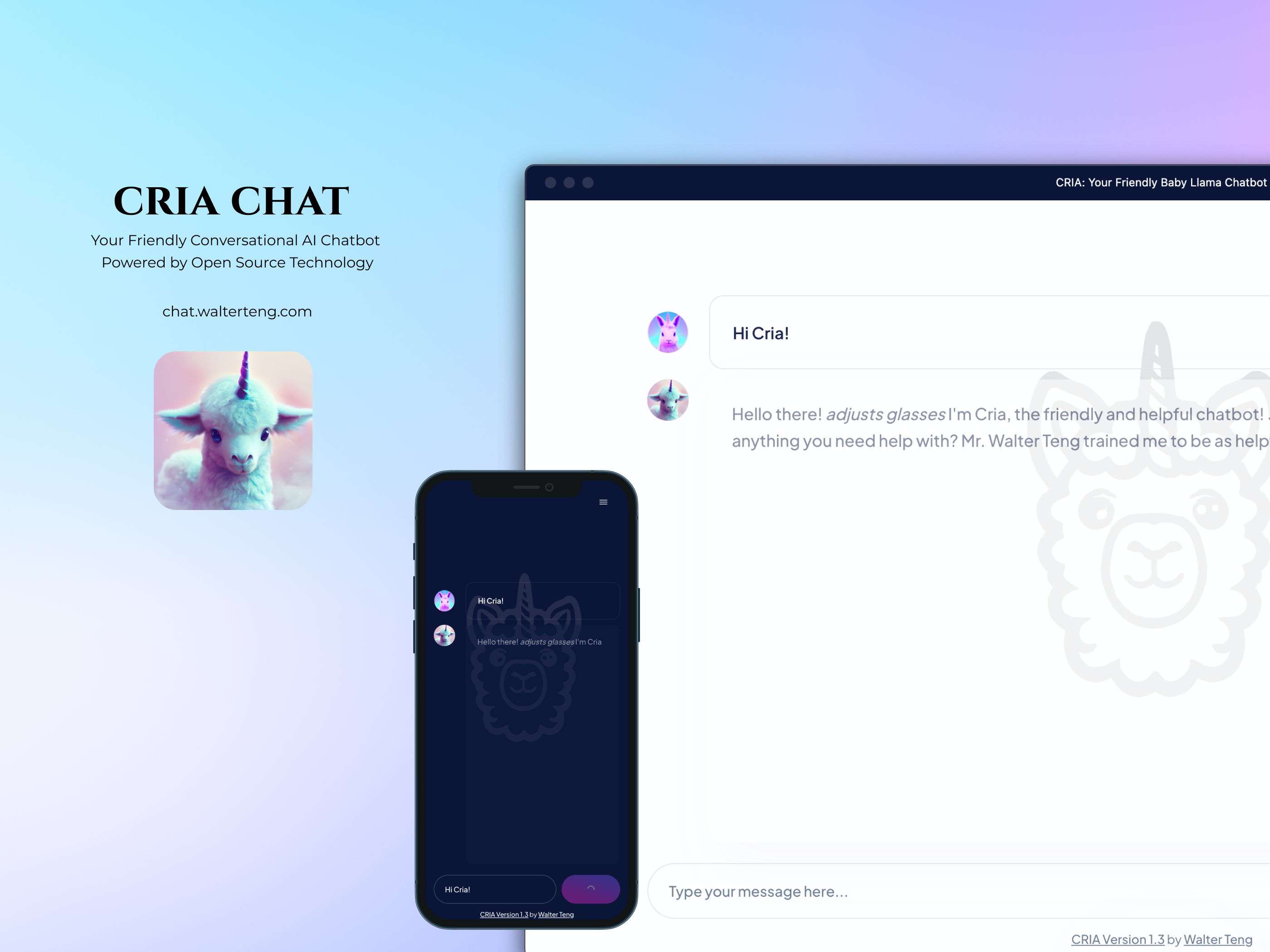
CRIA Chat
Available on:
2023 is undeniably an exhilarating time for AI engineers and enthusiasts alike. The field of Large Language Models (LLMs) has witnessed remarkable progress, pushing the boundaries of what artificial intelligence can achieve. Developing LLMs appears to be meant for large corporations and research labs. It may seem out of reach for individual contributors with limited computing resources. However, is this truly the case?
In this article, I am thrilled to introduce you to CRIA, an LLM project that aims to democratize AI and paves the way for individual contributors to create their end-to-end conversational chatbot in as little as one week.
Introducing CRIA
CRIA stands for "Crafting a Rapid prototype of an Intelligent LLM App using open-source resources." This name perfectly encapsulates the project's objective, emphasizing its accessibility and the speed at which you can prototype intelligent LLM-based applications with little to no cost today.
Additionally, the name CRIA pays homage to its foundational model, Meta's Llama-2 7b LLM. Like a baby llama, CRIA adopts a cheerful persona and strives to be an enjoyable conversational partner.
Features
Demonstration of Instruction-Tuning on LLM
CRIA goes beyond theory and demonstrates the implementation of instruction tuning on LLMs. Even more impressive is that you can achieve this using a free Colab instance, making experimentation and learning accessible to all, regardless of computational resources.
Fast LLM Inference with Server-Sent Events (SSE)
CRIA takes pride in its lightning-fast LLM inference capabilities, thanks to the implementation of Server-Sent Events (SSE). SSE ensures that user interactions with CRIA are not only swift but also real-time.
User-Friendly Modern Web Interface (PWA-Compliant)
CRIA's user-friendly modern web interface is Progressive Web App (PWA) compliant. This means that users can install the web-based app to interact with CRIA just like using a native app. The interface is designed to provide an intuitive and engaging user experience, making conversations with CRIA more delightful than ever.
Comprehensive Documentation
Detailed documentation is provided on the project's GitHub page to ensure developers can quickly dive into CRIA's capabilities. This documentation includes setup instructions, architectural diagrams, Architecture Decision Records (ADRs), and model evaluation details. It is an invaluable resource for those eager to explore and understand the inner workings of CRIA.
For a deeper dive into the various phases of CRIA's implementation, I have crafted companion articles that provide step-by-step guidance:
- How to Perform Instruction Tuning on Colab: This article walks you through the process of instruction tuning, helping you harness the full potential of your LLM. (Coming Soon!)
- How to Serve and Deploy LLM Inference via API: Learn how to implement your API server and deploy your LLM model for real-world applications. (Coming Soon!)
- How to Integrate a Next.js Front End and Deploy: This article goes through the integration process of Next.js, a modern web framework with the API server and deploying a user-friendly interface for your LLM-powered chatbot. (Coming Soon!)
Try CRIA Today
If you're eager to experience CRIA's potential, you have two options:
Cloud Version: Access CRIA on the cloud at chat.walterteng.com. Explore its capabilities and interact with your very own AI chatbot.
Local Deployment: For those who prefer to dive deeper, you can clone the CRIA repository and try it out locally.
References
Developing CRIA is an eye-opening experience, from distilling countless research papers and tapping into open-source community resources to fusing past experience to complete this end-to-end project. I would like to express my appreciation for the following individuals and resources:
- Research Papers: Countless research papers have guided me in navigating the evolving landscape of LLMs, from the development of LLMs to prompt engineering and instruction tuning.
- Maxime Labonne: His article and dataset have been instrumental in the project's development.
- Philipp Schmid: His detailed articles on instruction tuning and deployment on AWS have been invaluable.
- TheBloke: His quantization script demysterified the quantization process and helped to make deployment easier and faster inference.
- YouTube Community: Numerous YouTube videos have served as valuable learning resources for this project, and I encourage others to explore these videos to explore other possibilities with LLMs.